Harness Engineering: Das Tooling, das KI-Agents produktiv macht

Stell dir einen Bauer im Mittelalter vor. Er hat starke Pferde und einen guten Pflug. Aber ihm fehlt das Verbindungsstück – das Geschirr, das die Kraft der Pferde auf den Pflug überträgt. Ohne dieses Verbindungsstück stehen die Pferde nutzlos auf der Weide und der Pflug in der Scheune. Was macht der Bauer? Er baut sich ein Geschirr.
Dasselbe Problem haben wir heute mit KI. Die Modelle sind leistungsfähig, die Aufgaben liegen bereit – aber ohne das richtige Tooling dazwischen passiert nichts Produktives. Keine isolierten Umgebungen, keine Feedback-Loops, kein Aufgabenmanagement, keine Qualitätssicherung.
OpenAI nennt ihr Agent-Tooling "Harness". Das Wort bedeutet im Englischen so viel wie "Geschirr" oder auch "nutzbar machen" – und genau darum geht es: die rohe Kraft der Modelle für produktive Arbeit nutzbar machen. Und genau wie der Bauer bauen sich gerade alle, die ernsthaft mit KI-Agents arbeiten, ihr eigenes Geschirr.
Der eigentliche Engpass ist nicht das Modell. Es ist das Tooling drumherum.
Die Harness-Erkenntnis
Wer mit KI-Agents produktiv arbeiten will, merkt schnell: Das Modell ist nicht das Problem. Das Umfeld ist es.
OpenAI hat diese Erfahrung öffentlich dokumentiert. In ihrem Harness Engineering Artikel beschreiben sie, wie ein kleines Team ein internes Produkt komplett durch Codex-Agents bauen ließ: über eine Million Zeilen Code, 1.500 Pull Requests, null manuell geschriebener Code. Ihre Kernaussage:
"Early progress was slower than we expected, not because Codex was incapable, but because the environment was underspecified."
Der Großteil der Arbeit bestand nicht darin, bessere Prompts zu schreiben. Es bestand darin, das gesamte Umfeld zu bauen: isolierte Umgebungen pro Task, strukturiertes Wissen im Repository, automatische Architektur-Checks, automatisierte Code-Qualitätssicherung. Erst als dieses Tooling stand, wurde die Arbeit mit Agents produktiv.
"Humans steer. Agents execute." – so fasst OpenAI es zusammen. Die Rolle des Engineers verschiebt sich: weniger Code schreiben, mehr Umgebungen gestalten und Feedback-Loops bauen.
Das gilt nicht nur für OpenAI. Jedes Team, das ernsthaft mit KI-Agents arbeitet, macht diese Erfahrung.
Die Anatomie einer Agent Mission Control
Was braucht man eigentlich, damit KI-Agents produktiv und sicher arbeiten können? Hier die Bausteine:
Task-Management für Agents, nicht für Menschen
Viele Lösungen bilden einen Taskmanager mit Kanban-artigen Workflows ab: Aufgaben erstellen, priorisieren, Agents zuweisen, Status tracken. Das Grundprinzip ist bekannt – nur dass die Aufgaben nicht von Menschen, sondern von Agents abgearbeitet werden.
Parallel laufende Tasks müssen orchestriert werden. Nicht sequenziell wie bei Menschen, sondern echte Parallelisierung: fünf Agents arbeiten gleichzeitig an fünf Features, jeder in seinem eigenen Branch, mit eigener Umgebung. Das erfordert eine Task Queue mit Prioritäten, Retries und intelligenter Verteilung.
Fortgeschrittene Setups behandeln Tasks als strukturierte Arbeitsaufträge – versioniert, im Repository eingecheckt, mit Fortschritts-Tracking. Nicht nur To-Dos, sondern Execution Plans mit klarem Scope und Akzeptanzkriterien.
Isolierte Umgebungen pro Task
Jeder Agent-Task braucht seine eigene, saubere Umgebung. Das klingt selbstverständlich, ist aber der Punkt, an dem die meisten Setups scheitern.
Docker-Container sind das Minimum: eigener Workspace, eigene Dependencies, kein Crosstalk zwischen Tasks. Wenn Agent A eine Dependency kaputt macht, betrifft das nicht Agent B.
MicroVMs (z. B. Firecracker) sind eine Zwischenstufe zwischen Containern und klassischen VMs: Sie starten eine minimalistische VM mit eigenem Kernel und bieten dadurch stärkere Isolation als Docker, bleiben aber deutlich leichter und schneller als traditionelle VMs.
Hier zeigt sich ein fundamentales Dilemma: Tools wie Claude Code haben einen "dangerous mode" – auch liebevoll YOLO-Mode genannt. Er gibt dem Agent volle Ausführungsrechte, ohne bei jedem Befehl nachzufragen. Das ist für produktives Arbeiten als Agent praktisch zwingend nötig. Aber es ist gefährlich, wenn der Agent auf deinem lokalen Rechner läuft.
Die Lösung ist nicht, den Agent einzuschränken. Es ist, die Umgebung einzuschränken. Ein Agent darf alles tun – innerhalb seines Containers. Der Container begrenzt den Schaden. So arbeiten auch die produktivsten Setups: Jeder Agent bekommt einen eigenen Workspace mit temporärer Infrastruktur, die nach dem Task wieder gelöscht wird.
Multi-Projekt-Management
In der Praxis läuft nicht ein Agent auf einem Projekt. Es laufen dutzende Agents auf mehreren Projekten gleichzeitig. Das braucht:
- Ein Dashboard mit Übersicht über alle laufenden Agent-Tasks, deren Status, Ergebnisse und Fehler
- Ressourcen-Management – wie viele parallele Agents? Welche Modelle? Was kostet das gerade?
- Projekt-übergreifende Koordination – Tasks mit Prefixes (z.B. OVN-123, WEB-045), pro-Projekt Konfigurationen, getrennte Abrechnungen
Im Grunde ist das ein CI/CD-System für Agent-Arbeit. Statt Build-Pipelines orchestrierst du Agent-Durchläufe.
Review, QA und Feedback-Loops
Ein bewährtes Pattern: Durch Agents bearbeitete Aufgaben werden durch spezialisierte Review-Agents geprüft. Bearbeitung und Review passieren in einer Schleife – der Agent implementiert, ein Review-Agent prüft, gibt Feedback, der erste Agent bessert nach. So lange, bis alle Akzeptanzkriterien erfüllt sind. Das ist automatisierte Qualitätssicherung, kein Selbstlob. Der Mensch entscheidet weiterhin, was gemergt wird.
Dazu kommen automatisierte Tests als Gate – nicht nur klassische CI, sondern auch visuelle und semantische Checks. Lädt die Seite? Sieht der Button richtig aus? Ist die API-Response konsistent?
Der Mensch kommt nur noch ins Spiel, wenn echte Entscheidungen nötig sind. Aber dafür braucht es ein Eskalations-System: Der Agent muss wissen, wann er nicht weiterkommt, und den richtigen Menschen zur richtigen Zeit einbeziehen. Das ist Supervised Autonomy in der Praxis.
Deployment und Output-Management
Was passiert mit dem Output? PRs mergen, Container deployen, Artefakte archivieren?
OpenAI beschreibt in ihrem Harness-Artikel eine Welt, in der der Agent den kompletten Zyklus alleine fährt: Bug reproduzieren, Fix implementieren, validieren, PR öffnen, auf Feedback reagieren, Build-Fehler beheben – und am Ende selbst mergen. Das klingt beeindruckend. Aber sie schreiben selbst dazu: "This behavior depends heavily on the specific structure and tooling of this repository and should not be assumed to generalize."
Hier ist heute die Grenze. PRs mergen und live schalten muss noch durch einen Menschen passieren. Das ist kein technisches Problem – es ist eine Frage der Verantwortung. Wenn ein Agent eigenständig Code in Production schiebt, trägt trotzdem ein Mensch die Konsequenzen. Supervised Autonomy bedeutet: Agents dürfen den gesamten Weg bis zum fertigen PR autonom gehen. Aber der letzte Klick – merge und deploy – bleibt beim Menschen.
Rollback-Fähigkeit ist dabei nicht optional. Wenn ein Deployment schiefgeht, muss das System automatisch auf den letzten stabilen Stand zurückfallen können.
Praxis-Beispiel: Overnight Team
Theorie ist schön – aber wie sieht eine konkrete Umsetzung aus?
Ich habe Ende 2025 natürlich ebenfalls ein eigenes Agent-Orchestrierungssystem gebaut: Overnight Team. Nicht als Produkt für den Markt, sondern als internes Werkzeug, das genau die oben beschriebenen Bausteine zusammenbringt. Ein Blick auf die Komponenten zeigt, wie viel Infrastruktur nötig ist, damit Agents produktiv arbeiten können.
Overnight Team in Aktion
Hier am Beispiel meines Longevity-Startups newzapiens.com - aus Datenschutzgründen bereinigt, aber es reicht, um einen Eindruck zu bekommen.
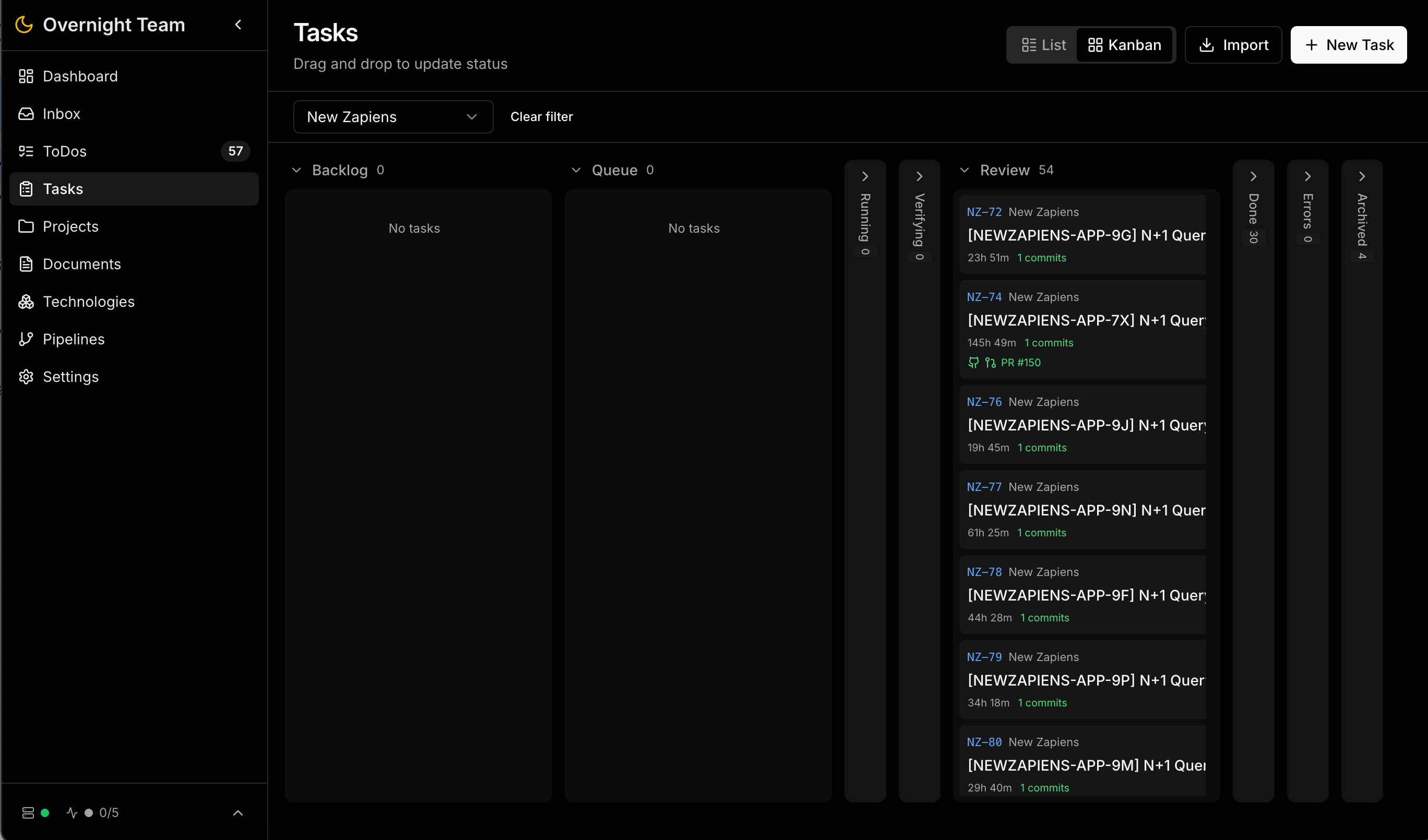
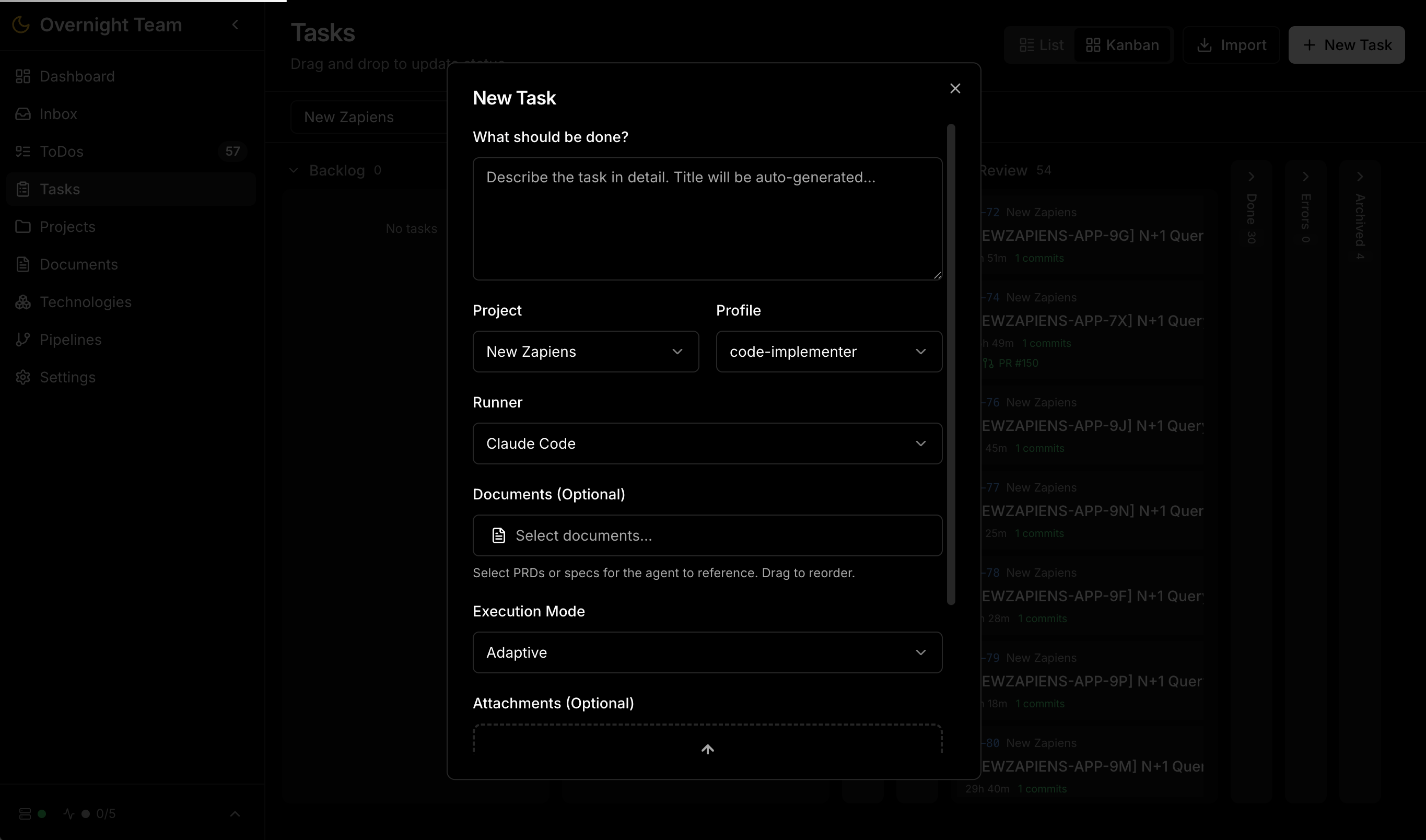
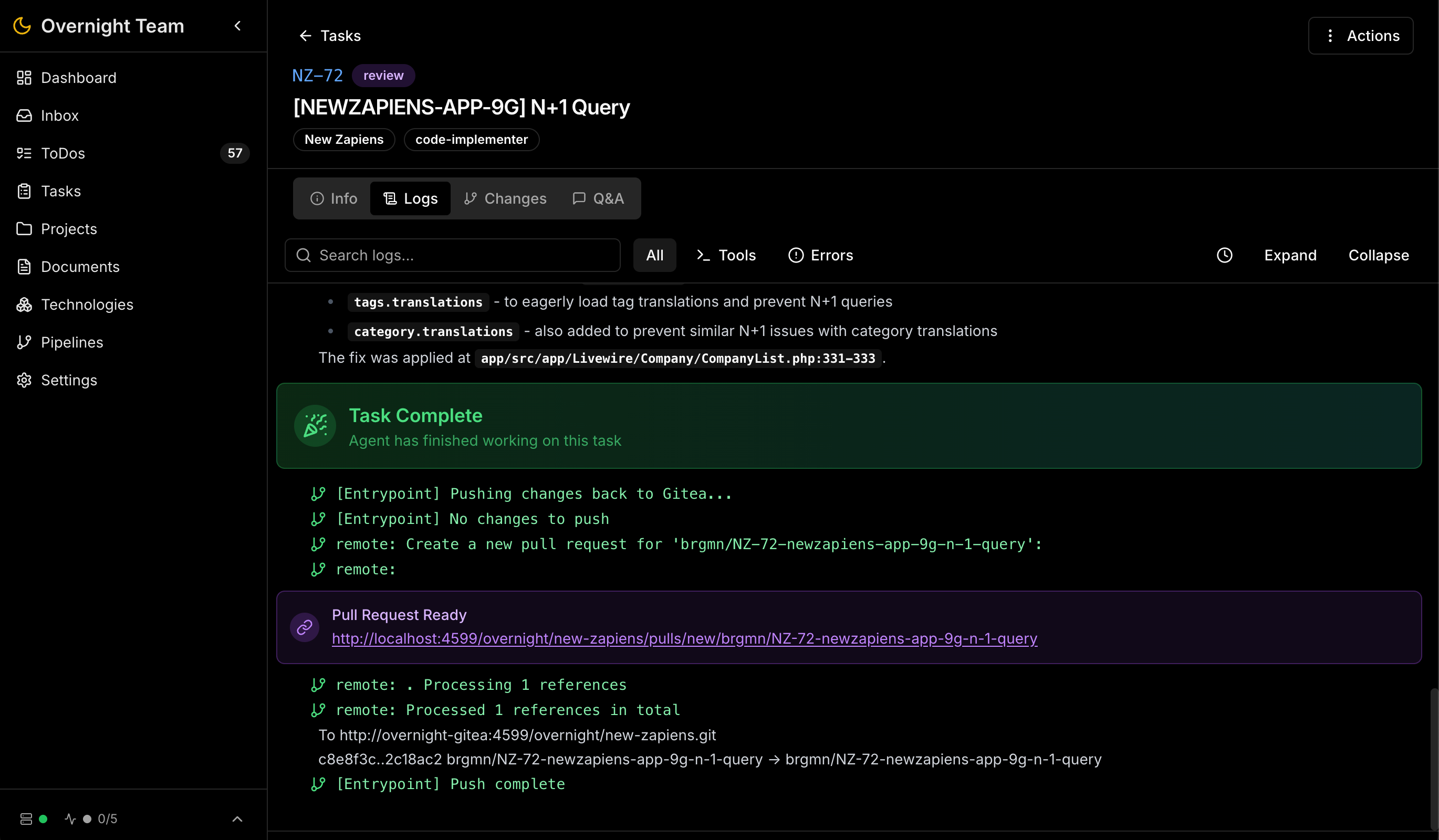
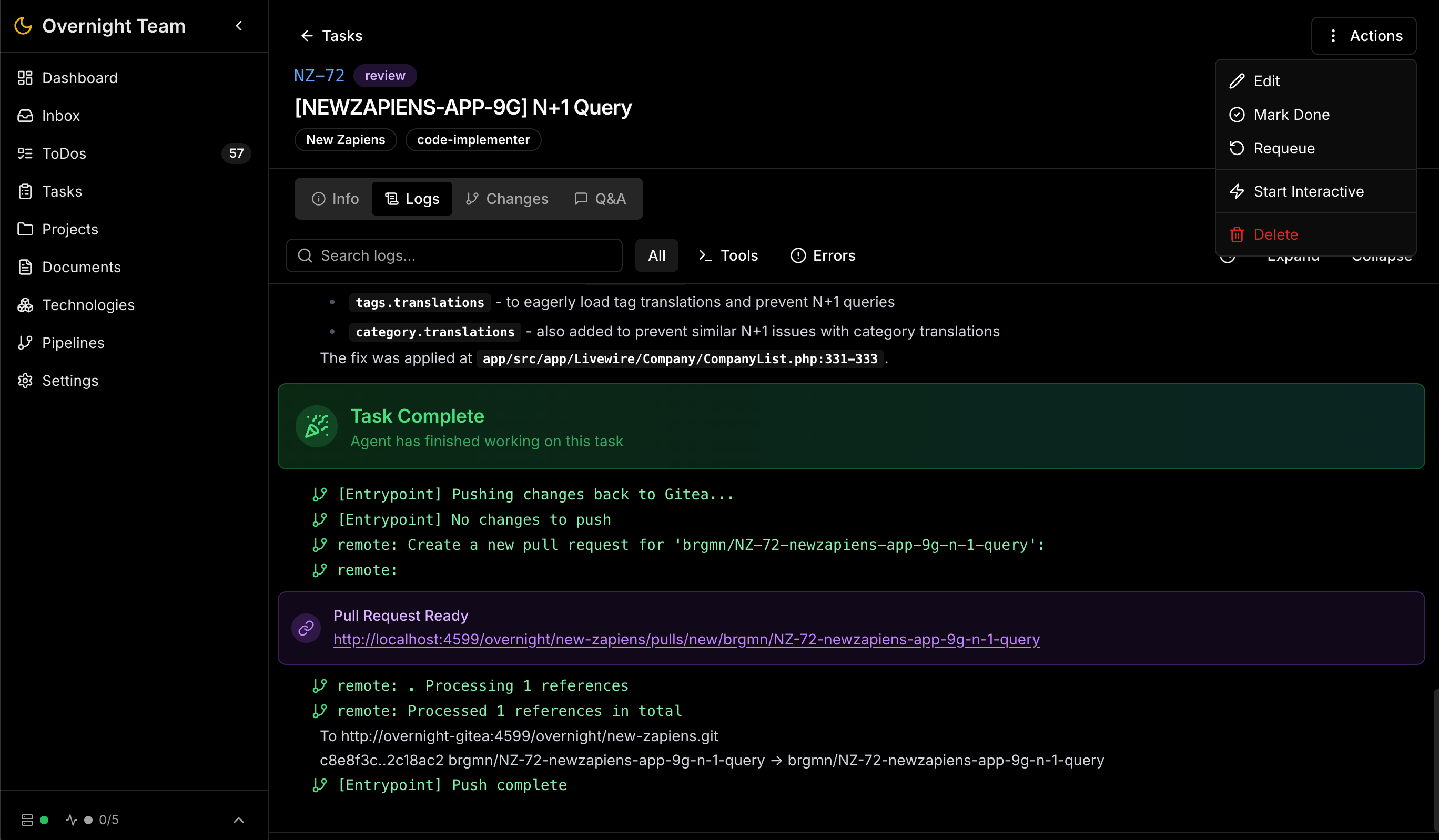
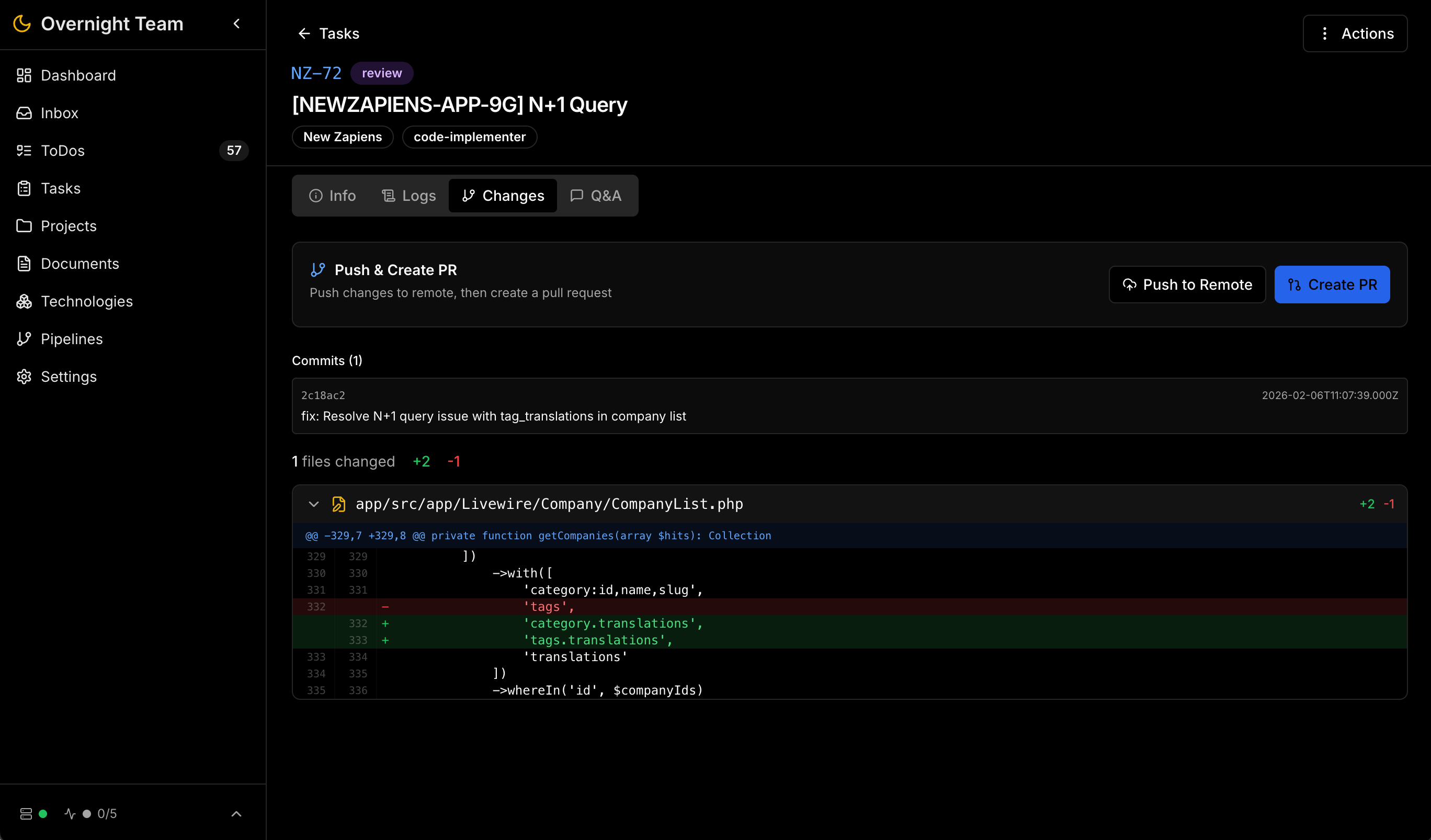
Das zentrale Projekt-Kanban-Board mit Aufgaben in verschiedenen Status – von Backlog bis Review.
| Baustein | Was es tut |
|---|---|
| Agent Orchestration | Spawnt Agents in Docker-Containern, Lifecycle-Management (starten, überwachen, stoppen), auswählbare Agent-Runner (Claude Code, OpenCode) und individualisierbare Agent-Profile (z.B. Code-Implementer, UX-Designer,...), Task Queue mit Prioritäten und Retries, Live Terminal-Streaming im Browser |
| Task Management | Kanban-Board (Backlog → Queue → Running → Review → Done), pro-Projekt Prefixe (z.B. OVN-123), Auto-Title-Generation, Verknüpfung mit externen Issues |
| Quality Assurance & CI | AI-Supervisor mit Pre-Check und Post-Review, interaktiver QA Chat mit Tool-Zugriff auf Code/Diffs/Logs, Multi-Level CI mit automatischer Feedback-Injection |
| Git & Version Control | Integrierter Gitea-Server, Branch Isolation pro Agent, AI-generierte Pull Requests mit Diff-Analyse |
| Remote Sync & Inbox | Bidirektionaler Sync mit GitHub/GitLab, Issues aus Linear, GitHub und Sentry als Agent-Tasks importieren |
| Cost & Billing | Token-Tracking pro Task und Modell, Subscription-Erkennung, monatliche Abrechnung pro Projekt mit CSV-Export |
| Documents & Knowledge | Dokumente versionieren und kategorisieren, automatische Qualitätsbewertung (0–100), Document Chat, Git Sync Status |
| Code Intelligence | Semantische Code-Suche via Embeddings und internem MCP-Server, Tree-Sitter-basiertes Code-Parsing, Library-Dokumentation als Agent-Kontext |
| Infrastruktur | Redis (Queue, Vector Search, Caching), SQLite/MariaDB, Docker Compose, verschlüsselte Credentials, Full Backup & Restore |
Die Ironie des Namens
Das Projekt heißt "Overnight Team", weil die ursprüngliche Idee war: Agents arbeiten die Nacht durch, während ich schlafe. Morgens liegen die fertigen PRs bereit.
Die Realität? Wenn mehrere Agents parallel laufen, sind sie oft in maximal 60 Minuten fertig – nicht 8 Stunden. Ich brauche aber meinen Schlaf.
Der Flaschenhals ist nicht die Ausführung. Es ist die Vorbereitung der Aufgaben. Specs schreiben, Akzeptanzkriterien definieren, Kontext bereitstellen – das dauert länger als die eigentliche Agent-Arbeit. "Humans steer. Agents execute." – am eigenen Leib erfahren.
Das ist viel. Sehr viel. Und das ist genau der Punkt: Ein produktives Tooling-Setup für KI-Agents ist kein Weekend-Projekt. Es ist ein eigenständiges Software-Produkt. Wer das unterschätzt, endet mit halbfertigen Lösungen, die mehr Probleme schaffen als sie lösen.
Warum alle dasselbe bauen – und warum das meiste Alpha-Software ist
Schaut man sich um, sieht man überall dasselbe Pattern: OpenAI (Codex Harness), Anthropic (Claude Code + MCP), Cursor, Devin, Factory, Augment – alle bauen Varianten derselben Grundarchitektur:
Task-Queue + isolierte Execution Environment + Feedback-Loop + Human Oversight Dashboard.
Das erinnert an die frühen Tage von CI/CD. Jeder baute eigene Build-Pipelines, eigene Deployment-Skripte, eigene Test-Runner. Dann kamen Jenkins, GitHub Actions, GitLab CI und konsolidierten den Markt. Wir sind in der "Jeder-baut-sein-eigenes-Jenkins"-Phase für KI-Agent-Orchestrierung.
Ein konkretes Beispiel aus der Open-Source-Community: Mission Control von Builderz Labs. 1.600 Stars auf GitHub, MIT-Lizenz. Deckt viele der genannten Bausteine ab: Kanban-Board für Tasks, Agent-Lifecycle-Management, Cost-Tracking, Claude Code Session Tracking, Pipeline-Orchestrierung, Multi-Gateway-Support. Die Community sieht die Lücke und füllt sie.
Das Ironie-Problem: Vibegecodetes Tooling für KI-Agents
Und hier wird es paradox. Viele dieser Mission-Control-Lösungen sind selbst "vibegecodet" – mit KI zusammengeklickt, kaum getestet, Alpha-Software.
Mission Control selbst trägt den Disclaimer: "Alpha Software — APIs, database schemas, and configuration formats may change between releases." Das ist kein Einzelfall. Die gesamte Tooling-Landschaft ist im Experimentier-Modus.
Wir bauen mit unfertigen Tools die Infrastruktur, um unfertige Agents zu überwachen.
Das ist nicht zwingend schlecht – so entstehen neue Software-Kategorien. Aber man sollte sich dessen bewusst sein. Für Unternehmen bedeutet das: Heute auf Patterns setzen, nicht auf spezifische Tools. Die konkreten Produkte werden sich noch mehrfach ändern. Die Architektur-Muster (Isolation, Feedback, Orchestrierung) bleiben.
Die versteckten Kosten: Vendor Lock-in, Datenschutz und Wartung
Vendor Lock-in – die neue Abhängigkeit
Jedes Tooling bindet dich an ein Ökosystem. Mission Control setzt auf OpenClaw, Codex läuft nur mit OpenAI, Cursor ist an eigene Infrastruktur gekoppelt. Wer heute sein gesamtes Agent-Setup auf ein Tool baut, steht morgen vor dem gleichen Problem wie Unternehmen mit Salesforce oder SAP: Migration ist teuer bis schmerzhaft.
Das Ironische: Die Modelle selbst sind zunehmend austauschbar. Heute Claude, morgen GPT, übermorgen Open Source. Aber das Tooling drumherum schafft die eigentliche Abhängigkeit.
Gegenmaßnahme: Auf offene Standards und eigene Abstraktionsschichten setzen. Dein Wissen (Company as Code) gehört dir, egal welches Tool davor sitzt.
Datenschutz – wo landen deine Daten?
Agent-Tooling verarbeitet zwangsläufig sensible Daten: Code, Geschäftslogik, Kundendaten, Credentials. Cloud-basierte Lösungen wie Codex oder Devin senden deinen Code an externe Server – für viele Unternehmen ein No-Go (DSGVO, Compliance, IP-Schutz).
Selbst gehostete Lösungen wie Mission Control lösen das Problem nur teilweise: Die Agents selbst telefonieren trotzdem zu OpenAI/Anthropic APIs. Jeder Prompt, jedes Code-Snippet geht über die Leitung.
Wirkliche Datensouveränität erfordert lokale Modelle (vgl. Local AI Artikel) oder On-Premise-Inference – was die Komplexität nochmals erhöht.
Minimum: Wissen, welche Daten wohin fließen. Kein Agent sollte Zugang zu Daten haben, die man nicht auch einem externen Dienstleister geben würde.
Administration und Wartung – die unterschätzte Last
Ein Docker-Container pro Agent-Task klingt elegant – bis man 50 Container am Laufen hat, die alle eigene Dependencies, Sicherheitspatches und Konfigurationen brauchen.
Alpha-Software wie Mission Control hat keine garantierten Sicherheitsupdates, kein SLA, keine Stabilitätsgarantie. Wer darauf produktiv aufbaut, erbt die Wartungslast.
Die Tooling-Schichten addieren sich: Host-OS + Docker/VM-Runtime + Agent-Tooling + Modell-API + eigene Integrationen = viele Stellen, die brechen können. Sicherheitsupdates für vibegecodete Alpha-Software? Bestenfalls sporadisch. Schlimmstenfalls gar nicht, weil der Maintainer zum nächsten Projekt weitergezogen ist.
Realitätscheck: Wer kein DevOps-Know-how hat, sollte besser auf gehostete Lösungen setzen und den Datenschutz-Trade-off bewusst eingehen – statt eine selbst gehostete Lösung aufzusetzen, die niemand patcht.
Der eigentliche Gamechanger: Anbindung an vorhandene Systeme
Die meisten Teams arbeiten nicht auf der grünen Wiese. Sie haben Linear, Jira, GitHub Issues, GitLab, Sentry, Datadog und Slack längst im Einsatz. Die spannendste Frage ist nicht "welches neue Tool brauche ich?" – sondern "wie verbinde ich meine bestehenden Tools mit Agents?"
Konkrete Szenarien, die heute schon möglich sind:
- Sentry meldet einen Bug → Agent bekommt den Stacktrace, reproduziert das Problem im isolierten Container, schreibt einen Fix, öffnet einen PR
- Linear-Ticket wird auf "Todo" gezogen → Agent liest die Spec, implementiert das Feature, erstellt PR mit Tests
- GitHub PR wird gemergt → Agent übernimmt das Deployment, überwacht Metriken, rollt bei Problemen automatisch zurück
- GitLab CI schlägt fehl → Agent analysiert den Fehler, fixt den Build, pushed erneut
MCP (Model Context Protocol) ist ein Enabler dafür: Ein standardisiertes Protokoll, um Agents an beliebige Tools anzubinden – ohne Custom-Integrationen pro Tool. Anthropic hat es vorgelegt, andere ziehen nach.
Das ist der Punkt, an dem Agent-Tooling aufhört, ein Nerd-Spielzeug zu sein: Wenn es sich nahtlos in den bestehenden Workflow einfügt, statt einen komplett neuen zu erzwingen. Agent-Arbeit wird unsichtbar. Du arbeitest weiter in deinen gewohnten Tools. Agents arbeiten im Hintergrund auf denselben Daten.
Voraussetzung bleibt: Company as Code als Kontext-Grundlage. Ohne dokumentiertes Wissen kann der Agent den Sentry-Bug zwar fixen – aber nicht beurteilen, ob der Fix zur Produktstrategie passt.
Was das für Unternehmen bedeutet
Du musst kein eigenes Tooling bauen. Aber du musst verstehen, was du brauchst. Die Grundlage bleibt dokumentiertes Wissen – Company as Code zuerst, Tooling danach.
Die Tool-Landschaft wird sich konsolidieren. Heute pragmatisch starten, nicht auf das perfekte Tool warten. Aber die Entscheidung zwischen Self-Hosted und Cloud, zwischen Open Source und kommerziell, zwischen maximaler Kontrolle und minimalem Aufwand – das ist eine der wichtigsten strategischen Entscheidungen gerade.
Drei Bausteine, die zusammengehören:
- Supervised Autonomy – Agents kontrolliert und sicher einsetzen
- Company as Code – Unternehmenswissen maschinenlesbar machen
- Das richtige Tooling – Mission Control, das Modelle mit produktiver Arbeit verbindet
Fazit
Das Modell ist nicht der Engpass – das Tooling drumherum ist es.
Wer heute die Patterns versteht – Isolation, Feedback-Loops, Orchestrierung, Integration in bestehende Systeme – ist morgen im Vorteil. Die konkreten Tools werden sich ändern. Die Architektur-Prinzipien bleiben.
Wie beim Bauer mit dem Pflug damals: Die Kraft ist da. Man muss sie nur nutzbar machen.
Weiterführend
- OpenAI: Harness Engineering – Was OpenAI intern über Agent-Tooling gelernt hat
- Mission Control – Open-Source Dashboard für Agent-Orchestrierung
- Supervised Autonomy – Agents sicher und kontrolliert einsetzen
- Company as Code – Unternehmenswissen als Grundlage für KI-Agents
KI-Workforce
Dein virtuelles Dev-Team mit CTO-Supervision
KI-Agent-Plattform as a Service – orchestriert und geprüft mit 20+ Jahren CTO-Erfahrung. Best practices statt roher KI-Output.